My research agent now runs six specialists in parallel. It used to do them one at a time.
Multi-agent orchestration just hit public beta. I upgraded the digest from #023. Six subagents, one lead, half the time.
In Field Note #023 I built a Claude Managed Agent that researches AI news while I sleep. One agent, six sources, one memory store. It worked. The problem was it worked sequentially -- Anthropic, then OpenAI, then DeepMind, one after another. One context window holding everything. One source waiting for the previous one to finish.
On May 6, Anthropic shipped multi-agent orchestration into public beta at Code with Claude. No access request. Just the managed-agents-2026-04-01 header.
I upgraded the same day.
What changed
Before: One agent running all six sources in sequence. Single context window. ~15 minutes total.
After: One lead agent delegating to six specialist subagents running in parallel. Each subagent has its own isolated context window and focuses on one source only. The lead agent reads the memory file while they run, then aggregates and deduplicates when results come back.

The screenshot below is the Anthropic Console session view from today's run.
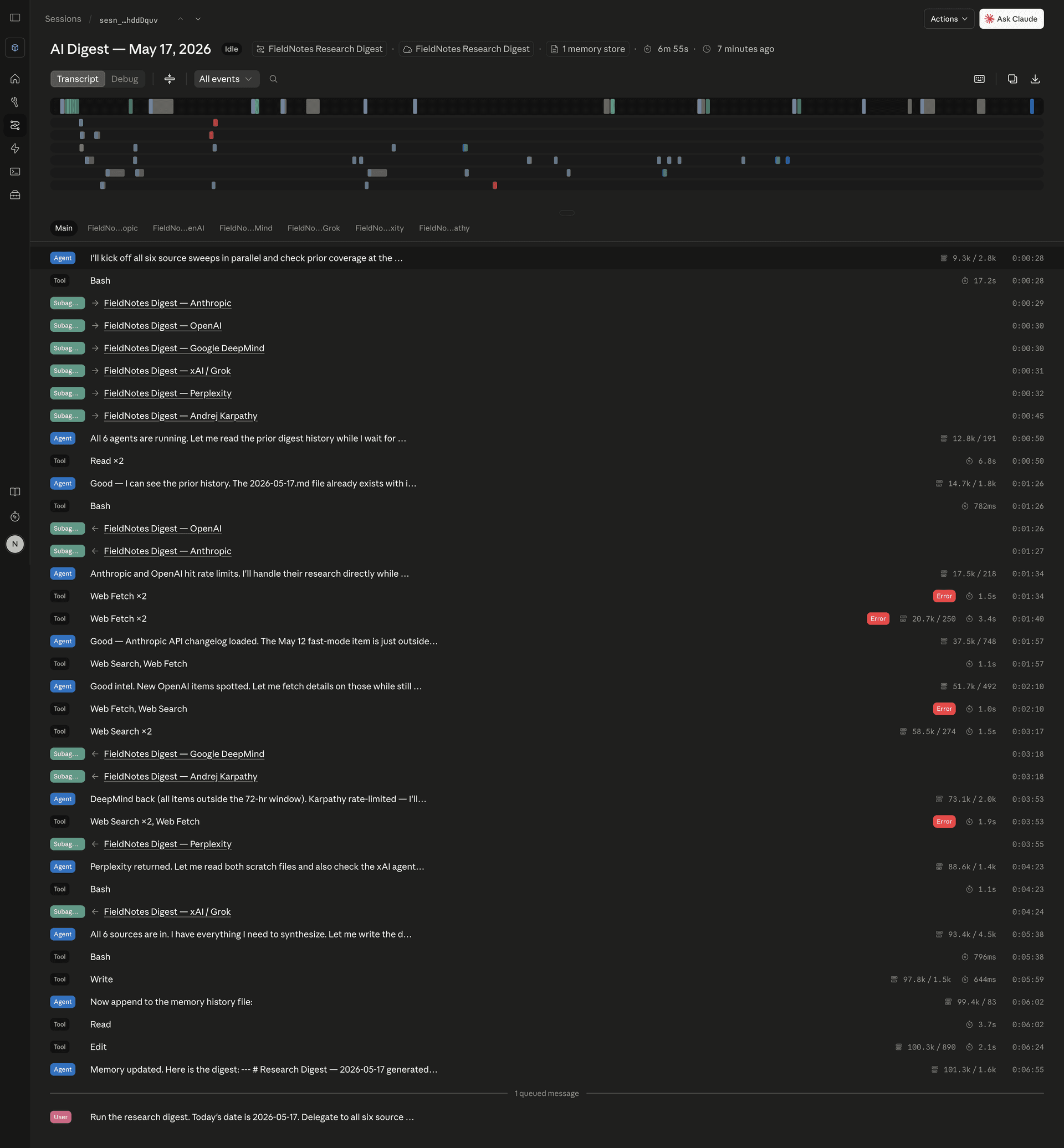
You can see the six subagents firing at 0:00:28 -- Anthropic, OpenAI, DeepMind, xAI, Perplexity, Karpathy -- all starting within seconds of each other. Results come back, aggregated at 5:38, digest written at 5:59, memory updated at 6:02, done.
Six minutes and fifty-five seconds. Down from fifteen.
Why isolated context windows matter
Each subagent only knows about its own source. The Karpathy subagent has no idea what the OpenAI subagent is doing. That is intentional. Smaller context, cleaner focus, better results per source. The lead agent is the only one that sees everything -- and only after the subagents finish.
This is different from cramming all six sources into one prompt and asking for a summary. The work is split and then merged, not held together from the start.
What is coming next
Two things I wrote about in #023 are still on the list.
Outcomes is next. I will define a rubric -- all six sources covered, items from the last 72 hours only, at least one Field Note candidate with a specific angle. A separate grader agent evaluates the digest against that rubric before the email sends. If it fails, the agent gets specific feedback and takes another pass. I will document exactly what changes when I add it and whether the digest quality improves in a measurable way.
Dreaming comes after that. Still in research preview, still gated. It would consolidate the memory files automatically between runs instead of me managing a growing list of history files. I have requested access.
The part worth noting
The Console view tells you something just by looking at it. Six colored bars firing in parallel, results converging at the lead agent, the whole thing wrapping in under seven minutes. This is not a script calling an API. It is closer to a team doing a job.
That shift in how I think about what I am building feels significant.