I'm adding search to this site. It will understand what you mean, not just what you typed.
I'm building RAG-powered semantic search for fieldnotes-ai.com. Before writing any code, here's the two-pipeline architecture and every decision behind it.
I have 16 Field Notes on this site. They cover git token leaks, RLS disasters, 65-million-token redesigns, unreleased Claude Code features, and a morning digest pipeline I built in a day. Useful stuff, if you can find it.
You cannot find it. There is no search.
The obvious fix is keyword search. It is also the wrong fix. If you type "deployment broke" you will not find the Field Note where I wrote "Vercel build failed." Same problem, different words. Keyword search does not know they are the same thing. Semantic search does. I am building RAG-powered search. You type a natural language question, get a synthesized answer, and see exactly which Field Notes it came from. This note documents the plan before I touch any code.
What RAG means in plain terms
RAG stands for Retrieval-Augmented Generation. The name is more complicated than the idea.
Before answering your question, the system finds the most relevant content first. That content gets handed to a language model as context. The model answers from what it retrieved, not from what it was trained on. The answer is grounded, citable, and honest about what it does not know. If there is no relevant Field Note, it says so instead of making something up.
Three things have to exist: a way to convert text into vectors that encode meaning, somewhere to store and search those vectors, and a language model to write the final answer. Everything else is plumbing.
The two-pipeline architecture
The system splits into two completely separate pipelines that share the same database and the same embedding service, but never call each other.
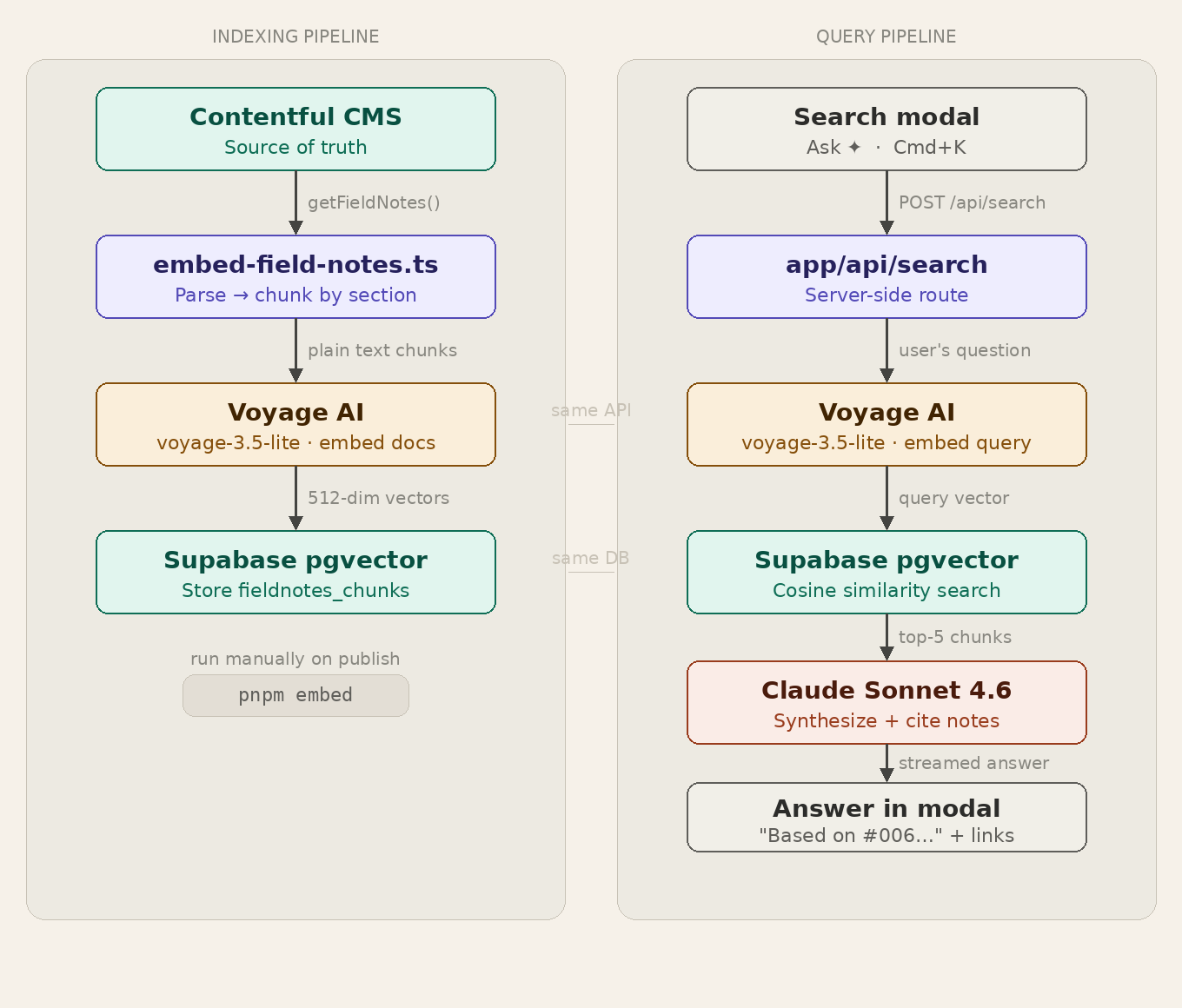
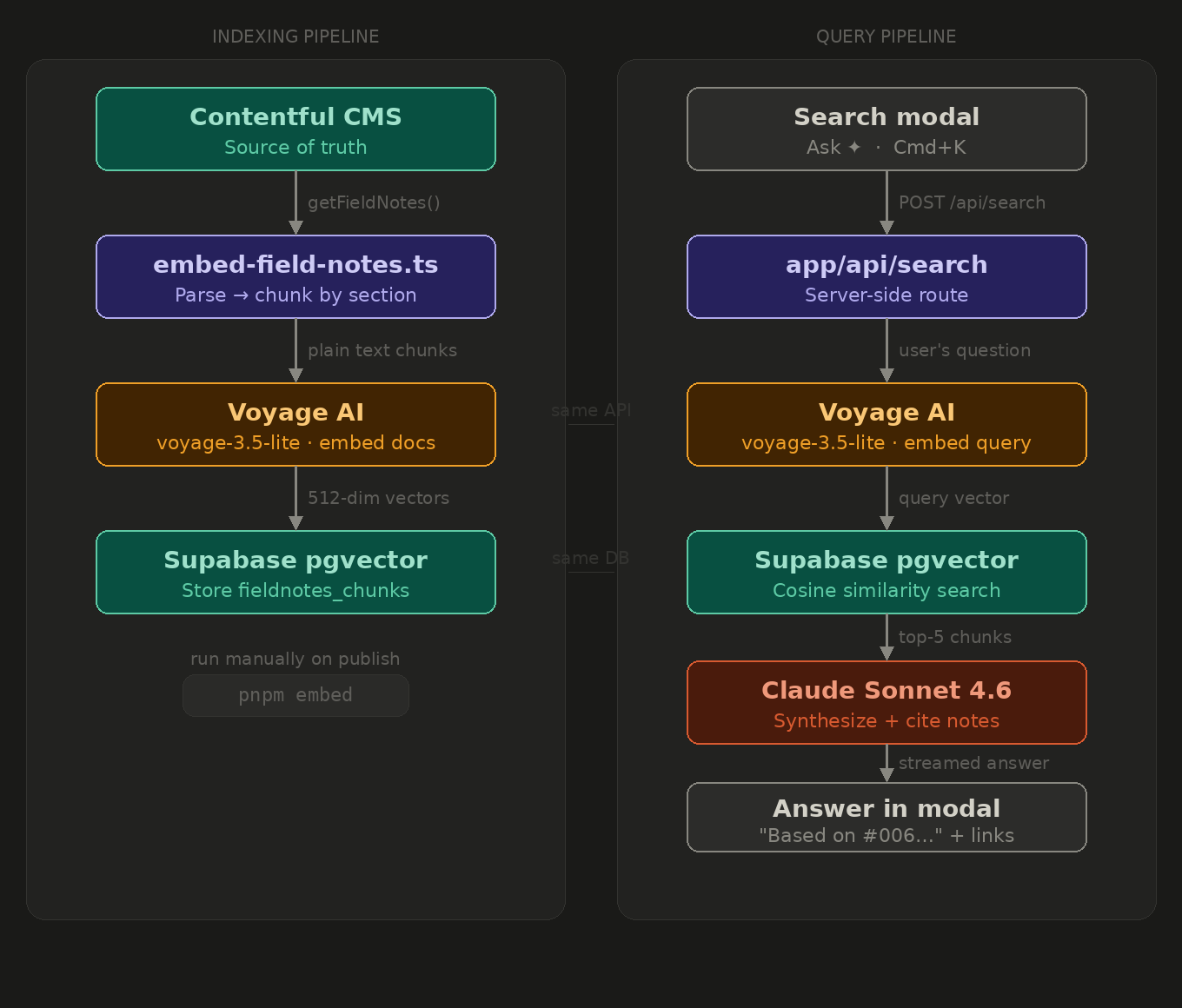
The indexing pipeline runs once per publish. It fetches all Field Notes from Contentful, splits each note by section header, converts those sections into 512-dimensional vectors using Voyage AI, and stores everything in Supabase. I run it manually with pnpm embed. At 16 notes and roughly 64 chunks total, this takes seconds.
The query pipeline fires on every search. A visitor opens the Ask ✦ modal, types a question, the browser calls a Next.js API route, that route embeds the question using Voyage AI, runs a cosine similarity search in Supabase, retrieves the top five matching sections, passes them to Claude Sonnet as context, and streams a synthesized answer back with Field Note citations inline.
The decisions I have already made
Embeddings: Voyage AI
Anthropic does not have their own embedding model. Their recommended partner is Voyage AI. voyage-3.5-lite outperforms OpenAI's text-embedding-3-large by about 6.3% on retrieval benchmarks, at $0.02 per million tokens. Every new account gets 200 million free tokens. My entire corpus fits inside the free tier indefinitely. Cost to run: zero.
Vector storage: Supabase
I already have Supabase running for the Morning Digest. One SQL migration adds a fieldnotes_chunks table with pgvector. No new accounts, no new billing. At 64 chunks, similarity search runs in under 20 milliseconds. Pinecone is overkill.
Chunking: by section header
Most RAG tutorials split documents into fixed 800-character windows. Field Notes have structure — section headers that act as semantic boundaries. Splitting by header means each chunk represents one idea, not an arbitrary slice. Each chunk stores its parent note number, title, and section name, so citations are automatic. This is also why I need to go back and add headers to any notes that are currently just flowing paragraphs before the pipeline runs.
Search UI: command palette
The entry point is an Ask ✦ button in the nav with Cmd+K as a keyboard shortcut. This pattern is called a command palette — Notion, Linear, and Vercel all use it. The sparkle icon signals AI rather than keyword search. The modal placeholder will include an example question so visitors know what kind of input it expects.
Synthesis: Claude Sonnet 4.6
The system prompt tells Claude to answer only from the retrieved Field Notes, cite specific note numbers inline, and say "I don't have a Field Note about that yet" when nothing relevant comes back. That last instruction is the most important one. Without it, the model fills gaps with plausible-sounding confabulation.
What comes next
The implementation is phased: Supabase schema, embedding script, API route, then the search modal. One Claude Code session. I will document the actual cost, token count, and anything that breaks.
After it ships I want to compare this from-scratch build to Contentful's native Content Semantics feature — which adds vector embeddings to content entries without any of this plumbing. Building it myself first means I will understand exactly what the abstraction is doing when I test it. That becomes Field Note #018.